The main goal of this research is to predict the relationships between two objects in an image and create a queryable knowledge representation, such that given the below image, the model should output the following graph:
Input

Output
Model Architecture
The model uses three features as depicted in the image below to calculate the corresponding scores, that is, visual score, spatial score and semantic score.
- Visual features : They represent the visual attributes of objects in an image and are helpful in finding out the relationships between objects. For example, man-book can have many relationships but if we have an image it can be boiled down to just one.
- Semantic features : They represent the subject-object pair. For example, we know that man-holding-book is more probable than man-under-book.
- Spatial features : They represent the position of objects in an image and are important in predicting relationships like on and under.
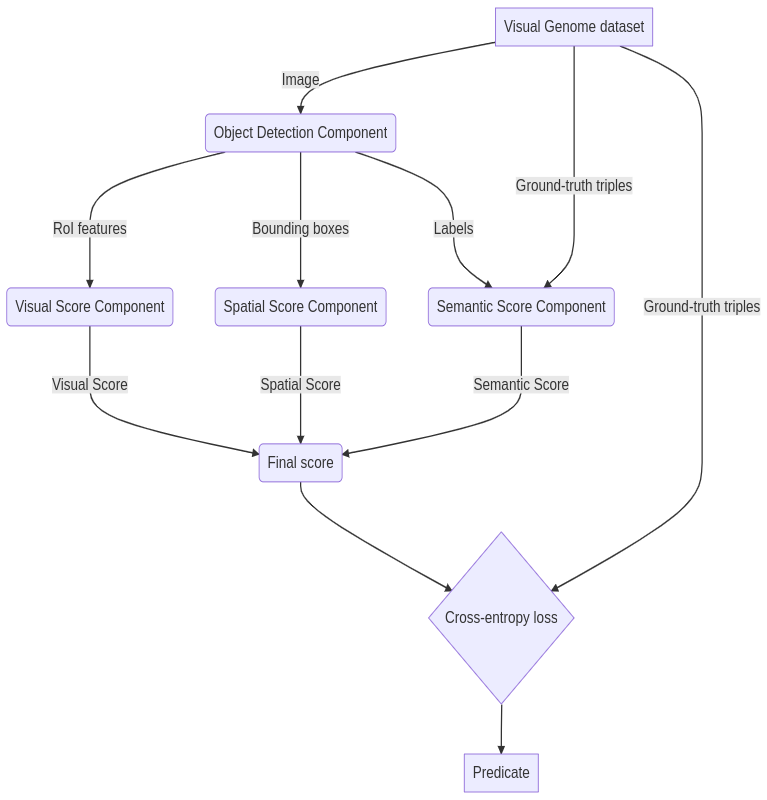
Once the above-mentioned features are used to predict the relationships between objects, a knowledge representation is generated from it.
Also, these graphs can be queried using functions :
- num_of_given_relation(G, predicate):
- triples_with_given_predicate(G, predicate):
- is_entity_present(G, entity):
wherein, G = graph, predicate = relationship, entity = subject/object
Use Case:
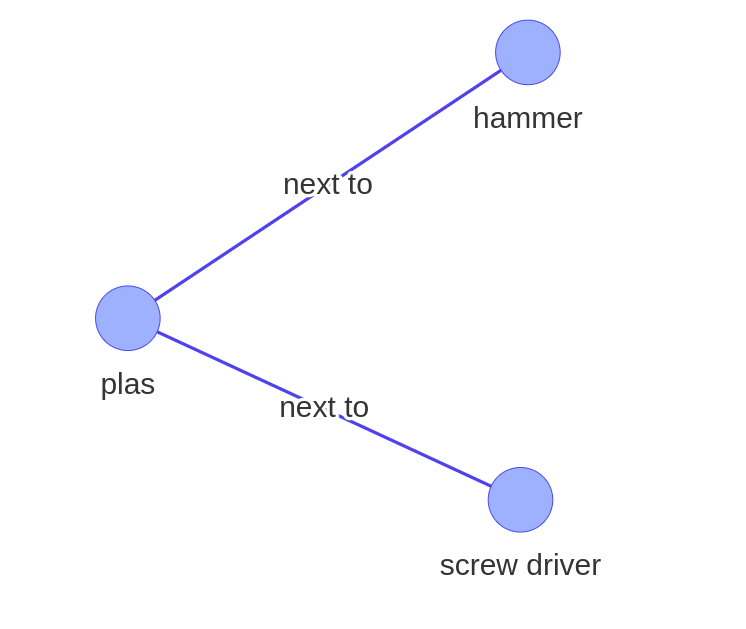
This use case is created using the graph depicted above:
[input]
triples_with_given_predicate(G, "next to")
[output]
hammer and plier are linked with the relationships next to
plier and screwdriver are linked with the relationships next to
This repository contains the code whose design is taken from An Interpretable Model for Scene Graph Generation and Relationship Proposal Networks.
Github repository: This work is done in collaboration with Toyota Europe so the code cannot be shared.